

My Friends,
A little off topic today. Sorry, but, for some, this may still be useful.
Artificial Intelligence, in particular NLP, Natural Language Processing, has a subcategory called Named Entity Recognition. This is a very useful tool, and it has many implementations, on many different platforms.
ML.NET 3.0 has implemented a trainer for NER, but the code is incomplete, and many have had a lot of trouble implementing it. I had a bit of a play with this and got it working. There is a good GitHub Issue Thread Here, that gives a bit of an idea on how to progress.
To make this work, you need to install the following packages:
<?xml version="1.0" encoding="utf-8"?>
<packages>
<package id="libtorch-cpu-win-x64" version="1.13.0.1" targetFramework="net461" />
<package id="Microsoft.ML" version="3.0.0-preview.23511.1" targetFramework="net461" />
<package id="TorchSharp" version="0.99.5" targetFramework="net461" />
...
</packages>
We need some helper classes to do some work on the data.
private class InputTrainingData
{
public string Sentence;
public string[] Label;
}
We need a Label class:
public class Label
{
// The Key: Person, Org...
public string Key { get; set; }
}
We need two classes to infer a sentence:
private class Input
{
public string Sentence;
public string[] Label;
}
private class Output
{
public string[] Predictions;
}
Here is the working class itself:
#region Using Statements:
using System;
using System.Collections.Generic;
using Microsoft.ML;
using Microsoft.ML.Data;
using Microsoft.ML.TorchSharp;
#endregion
public class Program
{
// Main method
public static void Main(string[] args)
{
try
{
var context = new MLContext()
{
FallbackToCpu = true,
GpuDeviceId = 0
};
var labels = context.Data.LoadFromEnumerable(
new[] {
// SpaCy Supported Types:
// See: https://www.kaggle.com/code/curiousprogrammer/entity-extraction-and-classification-using-spacy/notebook
new Label { Key = "PERSON" }, // People, including fictional.
new Label { Key = "NORP" }, // Nationalities or religious or political groups.
new Label { Key = "FAC" }, // Buildings, airports, highways, bridges, etc.
new Label { Key = "ORG" }, // Companies, agencies, institutions, etc.
new Label { Key = "GPE" }, // Countries, cities, states.
new Label { Key = "LOC" }, // Non-GPE locations, mountain ranges, bodies of water.
new Label { Key = "PRODUCT" }, // Objects, vehicles, foods, etc. (Not services.)
new Label { Key = "EVENT" }, // Named hurricanes, battles, wars, sports events, etc.
new Label { Key = "WORK_OF_ART" }, // Titles of books, songs, etc.
new Label { Key = "LAW" }, // Named documents made into laws.
new Label { Key = "LANGUAGE" }, // Any named language.
new Label { Key = "DATE" }, // Absolute or relative dates or periods.
new Label { Key = "TIME" }, // Times smaller than a day.
new Label { Key = "PERCENT" }, // Percentage, including "%".
new Label { Key = "MONEY" }, // Monetary values, including unit.
new Label { Key = "QUANTITY" }, // Measurements, as of weight or distance.
new Label { Key = "ORDINAL" }, // "first", "second", etc.
new Label { Key = "CARDINAL" }, // Numerals that do not fall under another type.
// Added Types by Me:
new Label { Key = "OBJECT" }, // An Object, Entity might be a Spoon, or a Soccer Ball. Needs Sub Categories.
});
var dataView = context.Data.LoadFromEnumerable(
new List<InputTrainingData>(new InputTrainingData[] {
new InputTrainingData()
{
// Testing longer than 512 words.
Sentence = "Alice and Bob live in the USA",
Label = new string[]{"PERSON", "0", "PERSON", "0", "0", "0", "COUNTRY"}
},
new InputTrainingData()
{
Sentence = "Alice and Bob live in the USA",
Label = new string[]{"PERSON", "0", "PERSON", "0", "0", "0", "COUNTRY"}
},
}));
var chain = new EstimatorChain<ITransformer>();
var estimator = chain.Append(context.Transforms.Conversion.MapValueToKey("Label", keyData: labels))
.Append(context.MulticlassClassification.Trainers.NameEntityRecognition(outputColumnName: "Predictions"))
.Append(context.Transforms.Conversion.MapKeyToValue("Predictions"));
var transformer = estimator.Fit(dataView);
var transformerSchema = transformer.GetOutputSchema(dataView.Schema);
string sentence = "Alice and Bob live in the USA";
var Encoded = Tokenizer.Tokenize(sentence);
// var trainedModel = context.Model.Load(GetOutputFilePath(), out DataViewSchema _);
var engine = context.Model.CreatePredictionEngine<Input, Output>(transformer);
Output predictions = engine.Predict(new Input { Sentence = sentence });
transformer.Dispose();
Console.WriteLine("Success!");
Console.ReadLine();
}
catch (Exception ex)
{
Console.WriteLine($"Error: {ex.Message}");
Console.ReadLine();
}
}
}
We need to instantiate the Tokenizer class:
#region Using Statements:
using Microsoft.ML.Tokenizers;
#endregion
public class Tokenizer
{
private static Microsoft.ML.Tokenizers.Tokenizer _instance;
private static EnglishRoberta Roberta = new EnglishRoberta("Data/encoder.json", "Data/vocab.bpe", "Data/dict.txt");
/// <summary>
/// .
/// </summary>
public static TokenizerResult Tokenize(string input)
{
Roberta.AddMaskSymbol();
_instance = new Microsoft.ML.Tokenizers.Tokenizer(Roberta, new RobertaPreTokenizer());
return _instance.Encode(input);
}
}
The files: "encoder.json", "vocab.bpe", "dict.txt", you can download via the links provided, and save them in a Data folder. Don't forget to copy to output directory.
The prediction is fairly accurate, with only two training examples, here is the prediction I got:
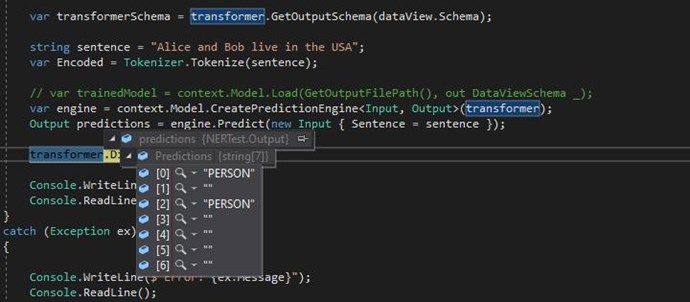
We should be getting:
new InputTrainingData()
{
Sentence = "Alice and Bob live in the USA",
Label = new string[]{"PERSON", "0", "PERSON", "0", "0", "0", "COUNTRY"}
},
At position [6] we should be getting: "COUNTRY". With some more training examples, this will improve drastically!
The EnglishRoberta class, encodes, or tokenizes words like so:
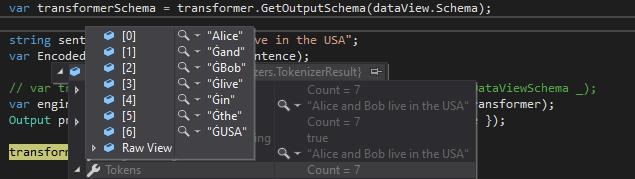
NER is a very useful tool, used in many areas in IT and Data Aquisition! It is useful for automatically extracting information from large texts!
Best Wishes,
Chris















